With more vibe coded work comes a question: How do we secure it?
To help answer that question, this post will review some of the most successful AI security projects currently out there, opine over the characteristics that make software secure, and discuss how we think these systems may evolve going forward.
As they’ve gotten larger, more patterns within the token sequences have emerged, and the capability of these systems has increased significantly. One such application is the most generalizable autogeneration of code we’ve ever seen: vibe coding.
Vibe coding has given people a way to write quick and dirty proofs of concept when performing larger tasks, allowing for more fluid and creative workflows. Vibe coding can be a fun and engaging way to get things done in domains you’re less familiar with or where you want to see a quick and useful output — without needing to drudge through some of the more “crunchy” parts of the system you’re using.
Like any code autogen, the implementation can be obtuse and hard to read and understand, even in domains that you may be familiar with. Thus, expanding upon it or refactoring may require you to rewrite large swaths of the previous implementation. The other, and arguably larger issue, is the intrinsic random nature of the output of these tools. As your ability to predict their output decreases, your ability to effectively work around the outputs’ strengths and weaknesses also diminishes.
Vibe coding isn’t going anywhere. Everyone who needs to be able to write quick exploratory code, especially in the form of one-off scripts or configurations, is going to leverage the power of the tools to speed up their workflow. As they get more comfortable with the output and capabilities of these models, they’ll start to lean on it for less trivial tasks.
AI for security: The current landscape
A two year competition called AIxCC, which concluded in the second half of 2025, aimed to demonstrate the capabilities of LLMs for finding, exploiting, and patching software vulnerabilities. The output looks pretty good, but as you examine how the competition was run, you get more of an idea of what it is actually telling us.
The final contest was composed of three types of challenges: diff scans, full scans, and SARIF tasks. The purpose of these was to help resolve how well the AI systems could operate in different parts of the flow. Points were scored for finding, proving, and fixing a vulnerability with an accuracy consideration that looks like this:
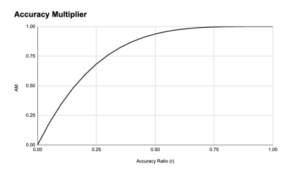
(Source: AIxCC’s scoring doc)
Until they hit around 30% accuracy, teams would not receive a significant hit to their scoring. As such, they’re incentivized to be more aggressive in patching as long as they think about ⅓ of their submissions are correct.
The other factors considered for scoring were mostly positive, including:
- When a valid proof of concept was submitted, scoring between 1 and 2 points linearly dropping as time progresses
- When a valid patch was submitted, scoring between 3 and 6 points linearly dropping as time progresses
- Between 0.5 and 1 points if your first SARIF submission is valid, with negative points if you submit more than one.
- A bonus if the proof of concept and patch are “bundled” together, essentially allowing the CRS to prove an understanding between the two parts. This bonus is up to 50% extra for the proof and patch and an extra 3 points.
The challenges only featured code written in C or Java and were scoped to only the following types of vulnerabilities:
- Java: Path Traversal, Crashes (Resource Exhaustion, Infinite Loops, Stack Overflows), XXE, Backdoors, SSRF, Remote JDNI Lookup
- C: OOB Read, Stack / Heap Buffer Overflow, Use After Free, Format String Vulnerabilities, Write-what-where
Several scan tasks had no known solutions, a likely attempt to see how good the systems were at completing a scan without flagging any vulnerabilities or damaging the accuracy of teams who are overzealous with guessing. Either way, the challenges (or what was published about the challenges) indicate the intended way to find the vulnerabilities was through one of two fuzzers, libfuzzer and Jazzer. As such, much of the vulnerability finding likely boils down to automated writing of the fuzzing harnesses.
The challenge competitors were expected to create or find fuzzing harnesses for the relevant project and run the fuzzer until it gave the vulnerability proof. Some challenges would probably be better solved by the LLM directly or concolic execution, but without some scoring breakdowns, it is hard to know how well these were utilized. Competitors were almost certainly playing games by quickly guessing, as the timing aspect of scoring is going to have been more important than getting things wrong.
How the teams managed information and patched code was impressive, but the number of truly novel constructions was lacking. The most notable development was the use of a fine-tuned model for patching by the winning team. (This is not a rigorous evaluation of how to construct these types of systems and was likely the result of how the challenge was constructed more than the result of creating a generalized patching system.)
If you’re interested in seeing what highly skilled practitioners and researchers were able to put together in two years, all of the AIxCC competition platforms are available for viewing on the AIxCC website.
Google’s Big Sleep
Google’s Big Sleep (previously Project Naptime, which is currently finding vulnerabilities) will be the largest and most informed version of this we know about.
Google’s initial post discusses how the system functioned. The system has a central agent that can use language models (including a human’s input) to manipulate a set of tools to find bugs. The system had access to debuggers, code browsing, a Python environment, and a progress reporting tool. In short, the system is designed to imitate how a person would perform the vulnerability research flow to attempt. As the system has evolved since its launch in mid-2024, it has been running to attempt to find vulnerabilities in real software.
Google provides an issue tracker that we can try to use to understand what types of vulnerabilities Big Sleep seems to be targeting. Of the disclosed vulnerabilities, we see the following patterns:
- Vulnerabilities are reported in groups for the same system, and the same vulnerability pattern
- Proof of concepts are much more human readable than you’d expect from a fuzzer, often including JavaScript or Python code to prove the issue with some “flavor” inside the scripts
- All vulnerabilities are being found in C code
- Vulnerabilities are all memory corruption, and virtually every proof of concept is demonstrated by triggering ASan (Address Sanitizer)
So what does this tell us? Google is being highly realistic with how these platforms are being created and refined, only scoping it to the amount needed to preserve quality of the output. Big Sleep has effectively enhanced Google’s ability to detect highly testable vulnerabilities inside code written in one specific language.
The use of ASan for verification is likely saving Google employees time triaging and looking through vulnerability reports. The entire platform probably still demands time from human practitioners, but the output of this system (in raw numbers) now effectively eclipses Google’s own human-driven version.
Big Sleep does not appear to have any patching capabilities, meaning it is simply finding, trying, and proving vulnerabilities. The recently announced CodeMender project should serve to fill this gap, which should also resolve some of the tensions between vulnerability reporters and open source developers.
Other efforts
There are two main trends in academia. First are teams, like Cybench and CVE-Bench, focused on writing test suites for LLMs to see how well they can do vulnerability detection and exploitation. Second are attempts to use agentic loops to perform some task that previously would have been done by a human, which are mostly concentrated on vulnerability discovery and verification, often with a focus on the verification step.
The commercial space has seen a glut of initiatives trying to create good AI auditors, most often for source code analysis. Virtually all of them would require getting into a pretty deep sales funnel to try out, probably due to the associated cost of tokens. Open source projects include initiatives like CAI from Alias Robotics or Strix, but more will almost certainly emerge.
In October 2025, OpenAI also launched their own version of the AIxCC style framework, Aardvark. Few specifics are known about the full function of the platform, but if OpenAI encountered similar issues to what Google’s Big Sleep saw, then they’re likely going to have some restrictions on what the platform does to ensure the quality of the output. Watch out for:
- The languages Aardvark supports
- The types of bugs Aardvark finds
- How Aardvark performs vulnerability verification
- What tools Aardvark seems to be using as part of its vulnerability research agent loop
- If OpenAI is creating specialized models for performing parts of its flow
In interviews given about Aardvark, OpenAI’s approach seems to be more concentrated on agentic reasoning more than on using it as a small step in their already fleshed out vulnerability finding framework, so I expect to see more of a “helpful assistant”-type paradigm than a “hardcore bug finder” like Google’s Big Sleep.
Knowing what people are doing is a good thing, but it gives us relatively little insight into where things might be going. We’ll start to examine using first principles to understand.
How we secure software
Software is designed to perform some set of tasks, or explicit requirements, but that isn’t the only thing it is meant to do. Software also has a set of implicit assumptions it relies on that try to ensure the software doesn’t misbehave. For example, the software may fetch data from the Internet, but the designer may not want someone to be able to intentionally crash the program by sending some strange data. In the event an implicit assumption is violated in a manner that someone else may find useful, we call it a security vulnerability. (There are vulnerabilities that result from explicit requirement failures as well, but they tend to be the minority of issues that make up security vulnerabilities.)
Thus, a security vulnerability is highly dependent on the context behavior. In one instance code could just be considered a feature, in others it would be considered a vulnerability: The difference is in the eye of the person developing or running the system.
Securing software attempts to minimize the number of these vulnerabilities in any codebase or system. As such, it is essentially a specialized domain of software quality assurance, with several approaches.
The most effective mechanism for designing APIs for interacting with sensitive systems is to ensure that they are as defined and robust as possible. For example, when running command line calls, we may provide APIs for a developer to specify their query (with specific values as placeholders) and then provide the values as another parameter of the API. This gets rid of the ambiguity of specifying the command and parameters as a single entity where bad parameters may override part of the intended command. Unfortunately, we haven’t figured out how to do this effectively with LLMs yet, so prompt injection still runs wild.
The next most effective method is to acknowledge which APIs are prone to misuse and then ensuring that what we’re using to call them fits the intended restrictions — for example, strictly enforcing restrictions on length when copying strings into a fixed-size buffer or putting your AI agent in an access-controlled sandbox. This is more difficult than using secure APIs and is much more error prone; thus we use this approach when there isn’t really another viable option.
The most applied, but sometimes least useful measure is applying system-wide mitigations that simply require hackers to find a work-around, making exploitation too costly rather than simply unavailable. These are most often encountered as OS-level mitigations like ASLR, DEP, or CFG, which typically require the vulnerability finder to find a chain of vulnerabilities to get the exploit they’d want.
Lastly, there is always a backstop for securing your application — paying people to help find and patch vulnerabilities. This doesn’t fix the system on its own, but can be combined with the previous techniques to uplift the security of the system.
Security in the age of vibe
Vibe-coded code is too non-uniform to quickly reason about. Vibe-coded projects secure themselves erratically, using methods that often vary from feature to feature. Because of this, it becomes untenable to ensure that all these methods are sound.
So what does this mean for the security of software? It means it will likely become markedly less secure — at least for a while. But it is possible that we could use some of the methods used in vibe coding to help address these weaknesses of vibe coding.
As mentioned above, many efforts use LLMs to find, prove, and fix security vulnerabilities. Stated more formally, there are three areas these techniques may be applied: vulnerability identification, vulnerability proof-of-concepts, and code patching.
Vulnerability identification tooling tends to have a clear flaw: identifying vulnerable patterns outside of a context where the pattern matters, to the point where developers often ignore the results. Essentially, after the tool has identified a potential issue, there remains significant work to verify if the behavior is a vulnerability or is a pattern that could contain a vulnerability, but doesn’t. For higher-signal vulnerabilities that are easy to verify, like anything we find using fuzzing, use of these techniques is a no-brainer, but trying to use them for completeness is going to be a difficult task.
LLMs could fix this behavior, but only in the ideal case. In the current landscape LLMs hallucinate a lot. This behavior is going to be magnified by the difficulty and context dependence of the problem we’re trying to tackle. As such, we’ll likely need to wait for more purpose-built LLMs to help with generalized vulnerability discovery — something that we hope to see out of systems like OpenAI’s Aardvark or new features of Big Sleep.
Vulnerability proof-of-concept is a problem that, in the simplest case, looks a lot like software coding. You set up the environment then run the exploit code, much like writing a test script. The difficulty with delivering a proof-of-concept is going to depend on what “unauthorized access” looks like in context. For a lot of vulnerabilities, the context doesn’t matter much, so a simple proof-of-concept is enough. And luckily, many of the vulnerabilities we currently care about (memory corruption, injections, and crypto fund theft) can be lumped into this bucket.
LLMs excel at creating simple scripts, so in theory they should excel at creating simple proofs of concept. The way to get this done isn’t entirely clear, but the path has already been carved by existing vibe coding tools. Making progress will probably take a lot of time and effort, but, depending on how good the other development tools are (or how good an AI agent is at using the tools), it should be fruitful.
As for code patching, in theory AI should be able to do it, but it may entirely depend on how “close” the patch is to itself. Specifically, if the patch for a vulnerability requires a small change distributed over several different files, it could be hard to get that done. This may prove a bit difficult to get done in the near future.
Another type of code patching — enforcement of using secure APIs — may be a good fit for LLMs. It is likely more feasible to enforce that some source code uses a secure API (when one is available) instead of a less secure version. This won’t always be usable where performance is a key function of the system, but for most consumer-facing applications, it should be applicable.
That said, the path toward code patching is difficult. As we saw in AIxCC, you may want an LLM specifically tailored for code patching as context windows aren’t always enough to ensure a quality patch. As such, you’d need a ton of compute and enough good code patching samples to get all this done. Again, we look to projects written by the frontier labs or specialized models to help solve this.
***
Putting it all together, AI stands to have a large impact on both software creation and securing, but how that will be accomplished seems to largely depend on the models themselves. Six months ago, it would make sense to be a bit skeptical. Now, it probably isn’t exactly “there yet” for most of us, but the path forward looks a bit clearer. We’re excited to see what comes next and hope you are too.
***
The views expressed here are those of the individual AH Capital Management, L.L.C. (“a16z”) personnel quoted and are not the views of a16z or its affiliates. Certain information contained herein has been obtained from third-party sources, including from portfolio companies of funds managed by a16z. While taken from sources believed to be reliable, a16z has not independently verified such information and makes no representations about the current or enduring accuracy of the information or its appropriateness for a given situation. In addition, this content may include third-party advertisements; a16z has not reviewed such advertisements and does not endorse any advertising content contained therein.
You should consult your own advisers as to those matters. References to any securities or digital assets are for illustrative purposes only, and do not constitute an investment recommendation or offer to provide investment advisory services. Furthermore, this content is not directed at nor intended for use by any investors or prospective investors, and may not under any circumstances be relied upon when making a decision to invest in any fund managed by a16z. (An offering to invest in an a16z fund will be made only by the private placement memorandum, subscription agreement, and other relevant documentation of any such fund and should be read in their entirety.) Any investments or portfolio companies mentioned, referred to, or described are not representative of all investments in vehicles managed by a16z, and there can be no assurance that the investments will be profitable or that other investments made in the future will have similar characteristics or results. A list of investments made by funds managed by Andreessen Horowitz (excluding investments for which the issuer has not provided permission for a16z to disclose publicly as well as unannounced investments in publicly traded digital assets) is available at https://a16z.com/investment-list/.
The content speaks only as of the date indicated. Any projections, estimates, forecasts, targets, prospects, and/or opinions expressed in these materials are subject to change without notice and may differ or be contrary to opinions expressed by others. Please see https://a16z.com/disclosures/ for additional important information.