Editor’s Note: In this series, we’re sharing two new innovations that can significantly speed up scaling and building applications in web3: Lasso and Jolt. Together, they represent a fundamentally new approach to SNARK design, improving on the performance of widely deployed toolchains by an order of magnitude or more; providing a better, more accessible developer experience; and making auditing easier.
For an in-depth introduction to these technologies, along with insight into their technical evolution, see this post authored by a16z crypto research partner Justin Thaler. Or find the research papers for Lasso and Jolt, respectively. You can also watch explainers on the lookup singularity and new ways to think about SNARK design.
Over the last few years, extensive research has gone into increasing the efficiency and usability of verifiable computing to deliver on the promise of trustless, distributed systems, and to address a critical barrier in web3 today: helping blockchains scale. While many theoretical applications have been proposed, they’re limited in practice by the efficiency of existing techniques.
SNARKs (Succinct Non-interactive ARgument of Knowledge) in particular have come far. But misconceptions and uncertainties about their performance, security, and need for specialized, often intensive engineering efforts still threaten the long-term adoption of this important technology. Because for web3 builders, SNARKs can unlock compute-intensive applications, allowing many more kinds of applications to be built than are possible now.
To address these issues and accelerate progress in the space, two new innovations, Lasso and Jolt, present a fundamentally different approach to SNARK design – one that is not only faster but potentially easier for developers to reason about and build on. The techniques described across the Lasso and Jolt papers represent a significant evolution from previous work. But what are they?
- Lasso is a new lookup argument (more on this below) with a dramatically faster prover. Our initial implementation provides roughly a 10x speedup over the lookup argument in the popular, well-engineered halo2 toolchain; we expect improvements of around 40x when optimizations are complete. To demonstrate, we’re releasing the open source implementation, written in Rust. We invite the community to help us make Lasso as fast and robust as possible.
- The second, accompanying innovation to Lasso is Jolt, a new approach to zkVM (zero knowledge virtual machine) design that builds on Lasso. Jolt realizes the “lookup singularity” – a vision initially laid out by Barry Whitehat of the Ethereum Foundation for simpler tooling and lightweight, lookup-centric circuits (more on why this matters below). Relative to existing zkVMs, we expect Jolt to achieve similar or better performance – and importantly, a more streamlined and accessible developer experience. With Jolt, it will be easier for developers to write fast SNARKs in their high-level language of choice.
In short: Lasso introduces a streamlined zkVM approach, avoiding tedious hand-optimized circuits by performing lookups against massive structured tables with less waste; and Jolt-based VMs are simple, fast, and easily auditable. Together these allow SNARKs for existing popular programming languages – not only those designed for the task.
So in this post, we share a brief primer on why SNARKs and zkVMs matter, plus some of the motivations and concepts behind Lasso and Jolt, along with key improvements and performance benchmarks. We then dive deeper into the Lasso implementation itself – which demonstrates how blockchain engineers and other developers can use and build on this tool today.
Why SNARKs and zkVMs matter, key concepts, and challenges today
Because many blockchain nodes verify and record every transaction, running computations on a blockchain can be extremely expensive. To avoid higher transaction costs, developers often perform the bare minimum on-chain computation to enable their application. SNARKs therefore have a central role to play in scaling blockchains by enabling applications to create receipts of expensive computations off-chain and only bear the cost of verifying the receipt on-chain. This is because the “succinct” aspect (the “s” in SNARK) means that these receipts are short, and can be verified with significantly less work than recomputing each and every transaction.
Despite recent advances, SNARKs are computationally expensive, difficult to audit, and inaccessible for most blockchain engineers (for instance, current approaches require a programming model that’s unfamiliar to even experienced developers). For more on these and other challenges with current paradigms in SNARK design, see this post.
The current state: To use SNARKs, developers often start by applying a frontend that transforms a computer program into a circuit – a system of polynomial constraints usable by probabilistic proof systems (the backend). In this approach, both the frontend and backend introduce significant overhead in terms of time and compute. So for performance reasons, many SNARK developers still write these circuits/polynomial constraints by hand. Other projects are taking a different approach, developing a toolchain that mimics the design of modern computers, which execute simple instruction sets such as ARM, x86, and RISC-V. Programs written in high-level languages such as Java, C++, and Rust, are compiled down to these instruction sets, so that they can be understood directly by silicon.
But there’s a good reason modern computers don’t expose CPU instructions to programmers. When writing in a high-level language, programmers have access to abstractions – like arrays, structs, and classes – which ensure that code is (relatively) easy to read and write. In contrast, CPU instruction sets provide only primitive operations such as ADD, MUL, OR, and JMP. Long sequences of these operations are easy to execute by silicon, but are difficult for humans to understand and execute without errors. Humans are actually bad at logic; the more logic that can be generated by a computer, the better.
This brings us to zkVMs: SNARKs that can prove correct execution of arbitrary computer programs specified in the assembly language of a specific CPU. A zkVM that supports an existing instruction set architecture – such as RISC-V or the EVM – can leverage existing compiler infrastructure from high-level languages down to assembly code for the VM. This results in a developer-friendly toolchain without requiring developers to build all the infrastructure from scratch. Developers can write programs in their language of choice, agnostic to the underlying internals of the SNARK and without worrying about bespoke hand-coded circuits.
To further understand the challenges and opportunities of SNARKs – and the impact of this work – it’s also worth understanding the significance of the lookup argument.
Understanding lookups
Compilers targeting CPUs regularly make use of operations which are inexpensive on silicon. But unfortunately, these operations can be very costly within a SNARK:
For instance, bitwise operations – which treat inputs to an instruction as a sequence of binary digits rather than a single integer – are nearly free on a CPU, but extremely expensive within SNARKs today.
Diagram of Bitwise OR for two 4-bit operands | source: a16z crypto
So to address this problem, researchers often use a technique known as a “lookup argument”. Rather than compute the bitwise instruction directly via additions and multiplications, lookup arguments precompute the outputs of the bitwise instruction on all possible inputs. Then, a zkVM applies a relatively cheap SNARK operation – aka “the lookup” – to verify that the current instruction lives within the pre-computed table. Doing so decreases the cost of the instruction.
Explanation of 4-bit (16 row) Bitwise OR table materialization | source: a16z crypto
The trouble is that an instruction like OR has two 64-bit inputs and a 64-bit output (see diagram above). This means that there are 2128 entries [editors’ note: that’s 340,282,366,920,938,463,463,374,607,431,768,211,456 entries] in the precomputed table. Simply materializing all of the possible combinations in such a table is entirely impractical, even with all the hard-disks in the known universe connected to your machine.
Instead, lookup arguments today are typically applied to tables sized at 216 at most and “chunked” together. But the chunking strategy adds significant overhead by:
- decomposing an integer into chunks
- requiring one lookup per chunk
- reconstructing an integer from the chunked lookups.
The additional complexity also significantly increases cognitive overhead for developers and auditors.
Explanation of chunking reduction strategy for an example 32-bit Bitwise OR table into an 8-bit table | source: a16z crypto
Another challenge for using lookup arguments – and this leads to the key insight behind Lasso – is that most of the entries in these enormous tables go unused. Yet provers must still “pay” for all those table entries that are never accessed. Even if a lookup table might be intractably large (say, 2128 entries), only a small fraction of its entries are actually looked up, unnecessarily increasing the costs.
That’s where Lasso and Jolt come in.
How Lasso and Jolt change the existing paradigm for SNARKs
Lasso enables a new strategy of efficient lookups over very large tables (such as the 2128 sized tables involved in 64-bit bitwise operations). Unlike existing lookup schemes, costs don’t grow linearly with the size of the lookup table regardless of how many entries are accessed. Rather, costs mostly grow with the number of lookups: Lasso efficiently proves lookups into this table, without ever materializing the table in its entirety.
Lasso has similarly low costs for all CPU instructions, not just the bitwise subset. The techniques to turn CPU instructions into Lasso lookups are described in Jolt.
Meanwhile, Jolt applies Lasso to an entire instruction set such as RISC-V or WebAssembly. The key insight is that most instructions can be computed by composing lookups from a handful of small tables. For example, the bitwise AND instruction on 64-bit operands can be reconstructed by splitting the lookup index into “chunks” and performing lookups into a smaller “subtable” containing the results of bitwise AND on 8-bit operands. As it turns out, all RISC-V instructions have similar structure and so their lookups can be proven using Lasso.
The result is a new paradigm for implementing zkVMs that was previously impossible because prior lookup arguments required (super)linear preprocessing or prover time.
The benefits of faster, more friendly SNARK design
In the past, the challenges outlined above – specifically, the cost of computing commitments and opening proofs over the entire lookup table encoded as a polynomial – has been a critical bottleneck for lookup schemes. As such, it has held back developers from building more compute-intensive web3 applications, which are only made feasible with highly performant SNARKs.
But there are many benefits that result from the innovations of Lasso and Jolt, including, as mentioned: (1) faster performance, (2) better and more accessible developer experience, and (3) easier auditability. We briefly elaborate on each of these below.
1. Faster performance
Lasso is not the first lookup argument implementation, but we expect it to be the fastest.
Our preliminary benchmarks, which confirm Lasso’s theoretical performance, are easiest to understand in comparison to existing implementations. We used halo2, the most widely used SNARK toolchain enabling lookups. Here, we show a benchmark of a 16-bit lookup table on a 2022 Apple M1 Pro with 16GB of RAM, comparing performance against halo2 backends.
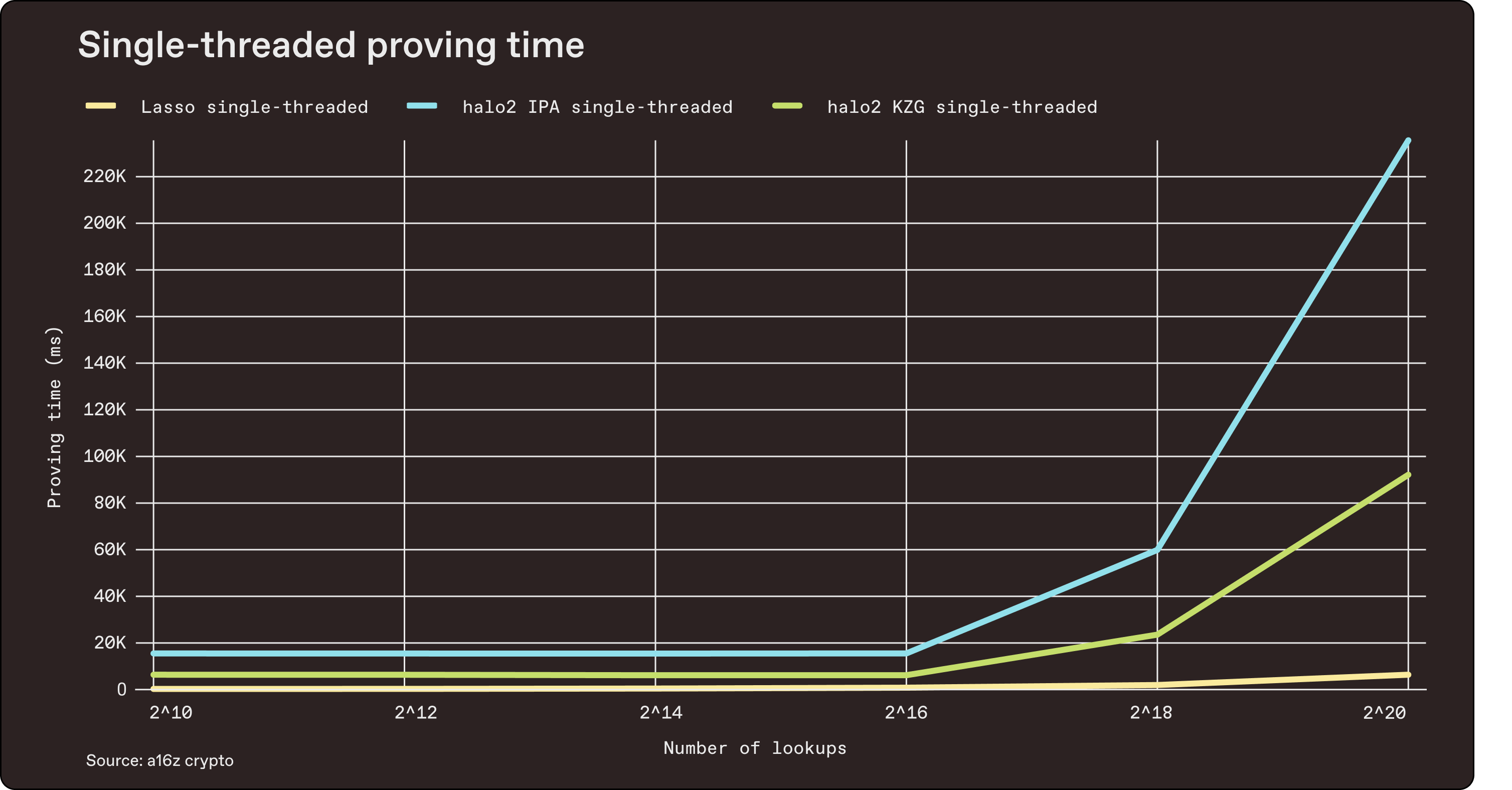 Benchmarked July 1, 2023 | source
Benchmarked July 1, 2023 | source
The main advantage of Lasso, however, is on much larger lookup tables – lookups that would otherwise be unusable in other frameworks due to the colossal costs associated with precomputation of lookup tables. Here is a benchmark of 1k to 1M lookups of a 2-operand 64-bit bitwise AND table:
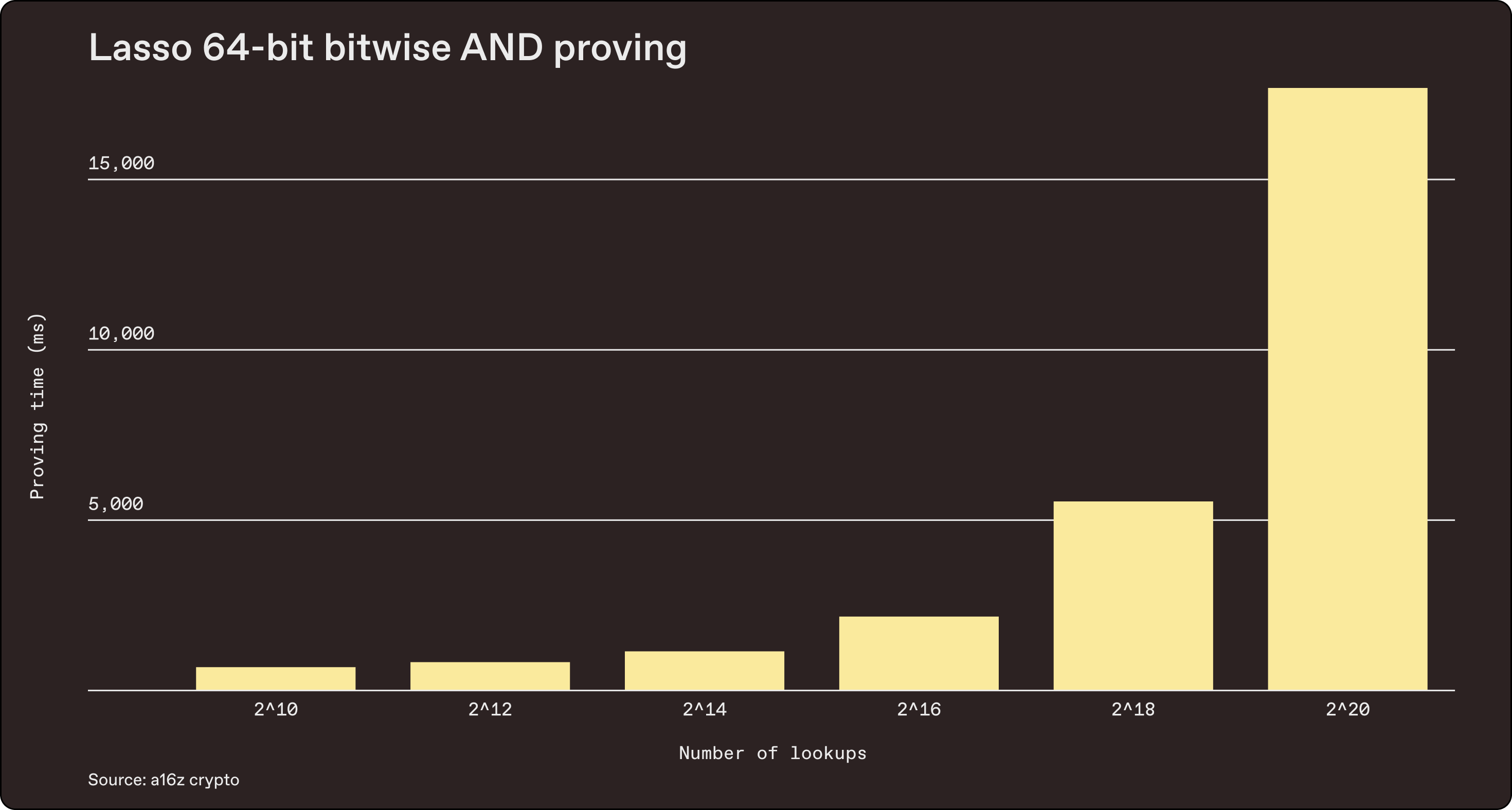 Benchmarked July 1, 2023 | source
Benchmarked July 1, 2023 | source
If we used halo2 or other existing lookup schemes directly, we’d have to materialize a table with 2128 rows, which is impossible (hence the chunking strategy described above). But with Lasso, we can now directly look up CPU instructions. Each CPU instruction maps directly to a single Lasso lookup.
Clean, simple, and efficient.
(2) More accessible developer experience
Lasso enables a more developer-friendly and auditable path toward implementing zkVMs than existing approaches.
Prior approaches to SNARK design involve formulating and hand-optimizing CPU instructions as circuits – a low-level and security-critical task requiring niche expertise in a domain-specific language. In contrast, developers across different language ecosystems should be able to pick up Lasso with relative ease.
This is because in Lasso, an instruction is defined by its subtable decomposition: its “big” lookup table can be composed from a handful of smaller “subtables”. And more importantly, such a decomposition can be concisely described in a high-level programming language. In our implementation, for instance, an instruction can be implemented in as few as 50 lines of Rust (e.g., bitwise AND). Moreover, many instructions across different instruction sets are conceptually the same, allowing significant code reuse – for example, WASM, EVM, and RISC-V all specify the same basic arithmetic, bitwise, and comparison operations.
(3) Easier auditability
The ways in which Lasso simplifies developer experience also make it more easily auditable than prior approaches. Auditability for zkVMs is especially valuable because many SNARKs today already secure significant monetary value on blockchains. Because Lasso implements instruction logic in Rust – rather than in bespoke circuits – and encourages code reuse across instruction sets, it concentrates the surface area to be audited to a relatively small and readable codebase.
Now that we’ve shared the state of SNARKs today and where Lasso and Jolt come in, we’ll now share more on how we translated Lasso from research paper into practice through an open source implementation. For those who would like to build more here, here’s a summary of our progress – along with a few technical details, challenges, and opportunities – and some suggested future directions for builders.
Notes on implementing Lasso
There’s plenty of work to do before realizing the full vision set out with Lasso and Jolt. But as of today, Lasso can be used for performant standalone lookup tables. In the near future, it will also be used to build entire zkVMs (the vision outlined by Jolt).
To demonstrate the potential, we’re releasing our open source implementation of Lasso. There’s still a lot to be done to improve and extend Lasso on the engineering front, so we welcome more open source contributors who are excited about the future of SNARKs.
From Spartan to Lasso
As mentioned in previous sections, Lasso leverages the “sparsity” of lookups to achieve sublinear prover runtime, as outlined in Setty’s Spartan paper. More precisely, Spark transforms any multilinear polynomial commitment scheme into one that is optimized for sparse multilinear polynomials.
To take advantage of their shared foundations, we built Lasso as a fork of the Spartan codebase. More specifically, we built on the Arkworks fork of Spartan, so that Lasso might benefit from the growing Arkworks ecosystem and vice versa.
MSM optimization
The performance of our implementation depends largely on multi-scalar multiplications (MSMs) required by the polynomial commitment scheme. An MSM is an operation involving group exponentiations commonly used in polynomial commitment schemes and SNARKs. Compared to prior lookup arguments, Lasso typically only needs to commit to small field elements.
We made modifications to Arkworks’ MSM algorithm to take advantage of this and achieve a ~30% prover speedup. Note that while our implementation currently uses Hyrax commitments, Lasso can be instantiated with non-MSM-based commitments as well.
Toward Jolt
We are currently working toward implementing Jolt alongside Lasso. To get to a full implementation, we need to implement every instruction in the instruction set (e.g. 40 instructions for the 32-bit RISC-V Base Integer Instruction Set –– plus eight for the Integer Multiplication and Division extension) as a composition of subtables. Doing so is as simple as implementing the SubtableStrategy trait.
So far we have implemented AND, OR, XOR, SLTU (unsigned less-than), and range check as examples. The process of implementing a new instruction is described in further detail in the repo.
What’s next
In addition to the work required to fully implement Jolt, there are many tasks that are in progress or up for grabs by other developers, including:
- Implementing/integrating different polynomial commitment schemes, such as multilinear variants of KZG (PST, Zeromorph, etc.), Dory, Ligero, Brakedown, and Sona (introduced in the Lasso paper)
- Implementing the grand product argument optimization described in Section 6 of the Quarks paper
- More extensive benchmarks, tests, and error-handling
- Using SNARK recursion to achieve efficient on-chain proof verification
These are just a few directions we see, but there are plenty of other opportunities to contribute! Or feel free to reach out to us with questions, ideas, and feedback: @samrags_ @moodlezoup.
***
The views expressed here are those of the individual AH Capital Management, L.L.C. (“a16z”) personnel quoted and are not the views of a16z or its affiliates. Certain information contained in here has been obtained from third-party sources, including from portfolio companies of funds managed by a16z. While taken from sources believed to be reliable, a16z has not independently verified such information and makes no representations about the current or enduring accuracy of the information or its appropriateness for a given situation. In addition, this content may include third-party advertisements; a16z has not reviewed such advertisements and does not endorse any advertising content contained therein.
This content is provided for informational purposes only, and should not be relied upon as legal, business, investment, or tax advice. You should consult your own advisers as to those matters. References to any securities or digital assets are for illustrative purposes only, and do not constitute an investment recommendation or offer to provide investment advisory services. Furthermore, this content is not directed at nor intended for use by any investors or prospective investors, and may not under any circumstances be relied upon when making a decision to invest in any fund managed by a16z. (An offering to invest in an a16z fund will be made only by the private placement memorandum, subscription agreement, and other relevant documentation of any such fund and should be read in their entirety.)
Charts and graphs provided within are for informational purposes solely and should not be relied upon when making any investment decision. Past performance is not indicative of future results. The content speaks only as of the date indicated. Any projections, estimates, forecasts, targets, prospects, and/or opinions expressed in these materials are subject to change without notice and may differ or be contrary to opinions expressed by others. Please see https://a16z.com/disclosures for additional important information.