Engineers building light clients will have to choose which properties to support in their protocols, and application developers will have to choose which light clients are the best fit for their use case. This section will explain how the most basic light client protocol works (SPV), and then dive deeper into the various properties of light clients protocols and their tradeoffs in security and performance.
Simplified Payment Verification (SPV)
SPV clients, considered the first light clients, were introduced with the invention of Bitcoin. They were defined in the original white paper to decouple client functionality, so that less powerful clients could interact with the network with as many security guarantees as possible. The approach is quite simple: Instead of downloading entire blocks with hundreds of transactions, as a full node would, an SPV client only downloads the 80-byte header for every block (10 mins per block, 800K blocks in total), and then asks a full node for transactions to/from the client’s addresses. Each transaction also comes with a Merkle proof, whose Merkle root is committed to in one of the block headers.
The client verifies the proof of work on each header to see that it’s the heaviest chain (the chain with the most proof of work on it), and thus that their transactions are actually on the canonical blockchain.
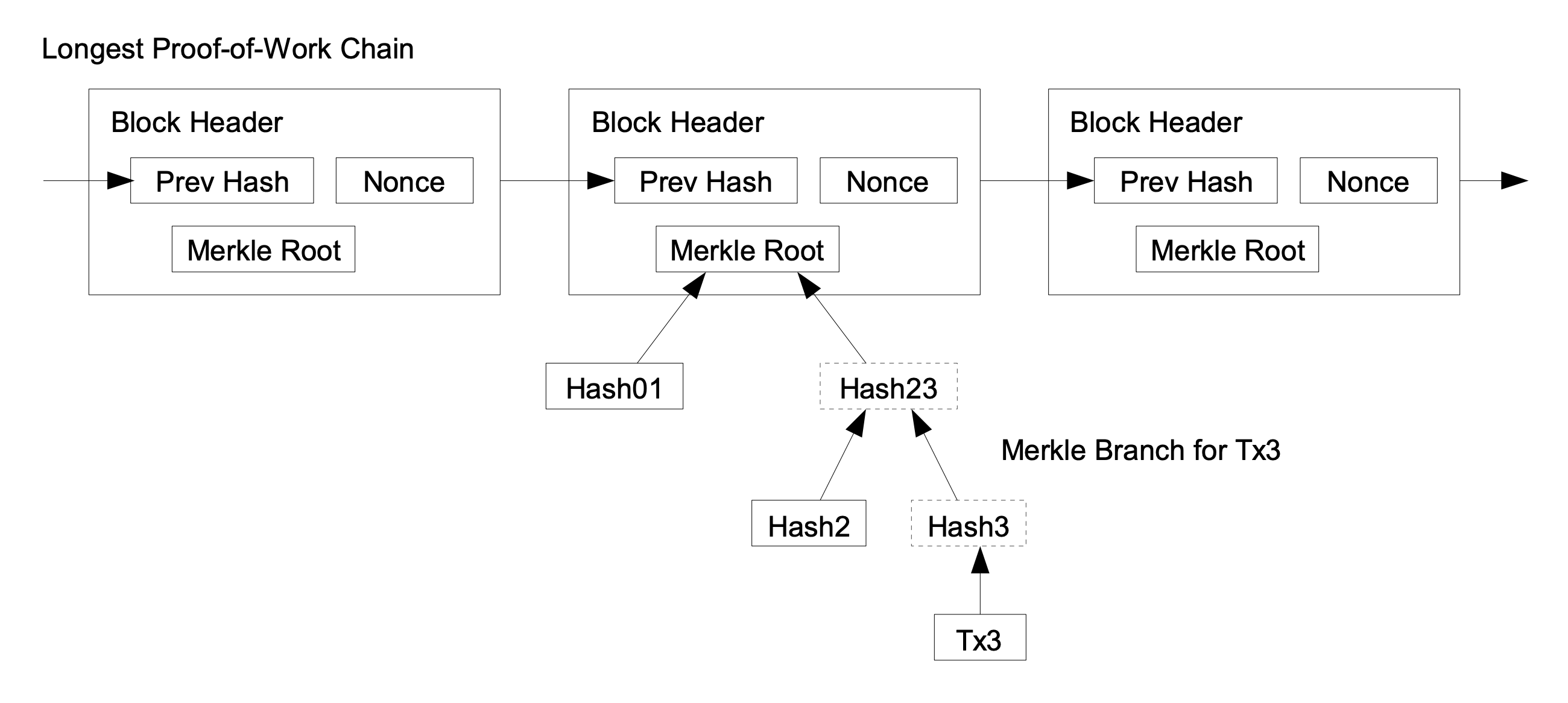
Bitcoin Whitepaper (Satoshi Nakamoto), SPV visualization
This approach is very secure, since it verifies objectively that real work was performed. Creating an alternate chain that looks real to a light client would require performing a similar number of hashes as all Bitcoin miners since the genesis block, or controlling close to half of the current Bitcoin hashpower. But SPV isn’t a fit for newer blockchain protocols for a few reasons: First, no real work is performed in PoS systems, so alternate blockchains can be created instantly. Second, SPV requires that every single header is validated, which is not especially efficient for newer protocols that have larger, faster blocks. And finally, the approach is not private, since all addresses are sent to the server.
The following sections explain some variations in light clients which help with these issues, and improve light clients more generally.
Objectivity vs weak subjectivity
With Proof-of-Work (and Proof of Space and Time, or PoST), clients can easily distinguish a fake chain from the real chain by cryptographically verifying that validators allocated a real resource for a certain amount of time. The honest chain objectively performed more work than the fake one. The same does not apply to PoS systems, where no real work is performed. Since Ethereum’s move to PoS, the genesis block and the Ethereum codebase are no longer sufficient to verify the blockchain. Now, checkpoints (or social information) are also necessary the first time a new client syncs. This is referred to as weak subjectivity.
Naive PoS algorithms are thus susceptible to “nothing-at-stake” attacks, where old staking keys with no current stake can be used to generate alternate histories at little or no cost and create long alternate chains. Attackers can also execute invalid state transitions to give themselves more stake, and create more fake blocks. To avoid these attacks, it’s necessary for light clients to rely on one or more trusted parties to report which chain is real. When syncing, a light client can start syncing objectively from a checkpoint, as opposed to the genesis block (weak subjectivity). Checkpoints can also be posted to a more secure chain like Bitcoin for transparency.
This approach has its challenges and benefits: Light clients would need to trust that the checkpoint is valid; however, even objective light clients that sync with the genesis block already introduce trust via the syncing application, the nodes they connect to, and more. Syncing objectively from a checkpoint is more efficient, since clients aren’t required to download all headers stored within the blockchain
There are other potential solutions to the nothing-at-stake attack that don’t require weak subjectivity. Some of these include key-evolving signature schemes (Cardano Ouroboros), VDFs (Solana, Chia), and timestamping on a separate chain (Babylon Chain).
Full validator set vs syncing committee
Running a light client requires validating the consensus algorithm (and thus validating block headers). For some blockchains, including Ethereum, this means tracking and validating the signatures of hundreds of thousands, or even millions, of validators – a process that makes clients drastically less “light”, since these proofs can take tens of minutes to download and validate. This is why Ethereum has developed a sync committee, a set of 512 randomly chosen validators that changes every 27 hours and signs block headers in a quickly verifiable way (Helios is one example). Since signatures are BLS, they can get aggregated for verification efficiency.
While sync committees are much more efficient for light clients, the Ethereum blockchain does not currently have a penalty for sync committee members that sign invalid block headers. So it’s possible for validators on the sync committee to accept bribes, or act maliciously by tricking light clients, without the consequence of the blockchain slashing their stake. Although Ethereuem does enforce an inactivity penalty for not signing anything at all, it’s not a meaningful percentage of the full stake. Even if there were penalties, they might not add sufficient security, since the sync committee can represent a small proportion of the stake (i.e. 512 vs. 800k validators in Ethereum).
Other systems do not rely on committees; for example, Cosmos IBC is an interchain protocol that defines a standard for chains to communicate with each other. These chains run light clients (verifying the entire validator set’s signatures, or at signatures representing 67% of stake, which can be very efficient if there is a significant long tail).
Manual validation vs SNARK proofs of consensus
One barrier to the broader adoption of light clients is the need to manually validate each block header and their consensus. This process requires clients to download a significant amount of data, which costs time, CPU cycles, and battery life. To improve efficiency, clients can instead validate a SNARK (zk) proof that a block header is valid. Instead of validating each header and consensus signature, SNARK light clients validate a proof that someone else knows a header chain and the signatures that are required to make a block header that hashes to block hash H. For some types of SNARKs, validation is constant time and can be under 100ms.
These proofs are ideal for bridge light clients, where resource constraints are restrictive, and a full light client might be too expensive. The proofs are also much faster and cheaper than downloading tens or hundreds of MBs of data to sync up.
There are several SNARK libraries currently in development that aim to verify both sync committee light clients and full consensus light clients, which makes it even faster to sync to the Ethereum blockchain. For certain blockchains like Bitcoin, Near, or Cosmos, these proofs are already practical to generate; several companies, including Succinct, Polyhedra/LayerZero, and Electron, are making significant progress.
Although this work has come far in recent years, it’s not yet practical in production for all blockchains. SNARKs proving consensus takes tens of minutes, even with hundreds of GPUs, so progress in this area is important (and happening quickly).
Risks of SNARK bridges
The complexity of current SNARKs introduces a few different layers of risk for light clients. Critically, a bug in a SNARK’s circuit, math, or software, could be catastrophic for bridges, which are often part of financial infrastructure and trusted with user funds. Also, some SNARK proof systems have additional cryptographic assumptions or trusted setup, which does slightly increase the risk surface. For example, zkSync’s system assumes that at least one member in the setup ceremony behaved honestly and threw out the keys. Also, SNARKs do not guarantee that the proved header is on the longest chain (we’ll talk about this below).
Finally, SNARK consensus proofs do not reveal the signatures within the block headers to the verifier (the light client in this case), which makes it difficult to penalize bad actors. If validators sign invalid blocks to create a fake proof, the light client would not be able to submit evidence of this to the source chain; and the source chain would not be able to slash the validators’ stake. With no economic incentives for signers to be honest, light clients are significantly less secure. Data availability (DA) committees can help here by ensuring that the signatures are posted somewhere at a cheap price and allowing the system to punish bad actors.
Which headers to validate
SNARKs, as we’ve described above, can make validating each block header more efficient, but validating millions of headers is still impractical (if not impossible) given bandwidth, CPU, and time constraints. With some PoS systems, light clients can start syncing at a checkpoint near the tip of the chain in order to validate fewer headers and therefore drastically reduce the time it takes to sync.
Furthermore, in most PoS protocols there are limits to how quickly the validator set can change, which is another way to make validation significantly more efficient. In one of these protocols, the client can fast-forward enough blocks such that no more than n% of the stake weight could have possibly withdrawn. If the block at that point has more than 67+n% of the stake-weight, it is guaranteed to be valid even if the n% of stake has withdrawn. From there, the client can download the new validator set (assuming there is a commitment to it) and verify it, to refresh.
There are also several protocols such as FlyClient, Non-Interactive Proofs of Proof-of-Work (NIPoPoW), and succinct non-interactive argument of chain knowledge (SNACKs) that work well for the PoW/PoST objective ecosystems. These only have to download and verify O(log(N)) headers, where N is the height of the chain. Flyclient clients (for example on Chia) work by sampling block headers throughout the chain based on their difficulty, and use a Merkle mountain range (MMR) to commit to headers in the past. If the prover tries to fake a non-negligible number of blocks from the real chain without having a correct proof of work, one of the sampled headers will fail to validate.
PoPos is a solution that enables light clients to sync with the finalized header chain in Ethereum and PBFT-style PoS protocols succinctly by downloading only logarithmic (in the number of blocks) amount of data from the full nodes. Compared to the sync committee construction of PoS Ethereum, software like Kevlar that implement this can improve communication by 180x when syncing after 10 years of consensus execution.
Proofs of execution and data availability (DA)
Three things need to be proved in order for clients to verify state: Consensus (validators selected a block), execution (the block transactions were applied correctly), and data availability (nodes are storing the block data).

Even with light clients that verify consensus proofs (covered in the previous section), the validators still need to be trusted to execute transactions correctly and have block data available. This is not safe to assume in systems with large blocks: If the client doesn’t validate execution and DA, a malicious validator set could claim that invalid state is valid.
One way to reduce these assumptions is for someone to create SNARK proofs of the entire transaction validation and execution logic, proving to the light client that applying transactions to the state hash of block N results in the state hash of block N+1, and the corresponding block header. It is worth noting that the creation of these execution proofs is even more computationally intensive than SNARKS of block headers, and this field is still early. These proofs can take tens of minutes to generate, even using data centers with hundreds of GPUs.
Some systems, like those pioneered by Celestia and EigenDA, leverage DA proofs, which allow the client to sample and verify a few random pieces of data, ensuring that validators have not deleted the data. These DA light clients can provide statistical guarantees that the whole block is available. Why this is important: In certain blockchains with high data throughput, lazy nodes might not store any data at all, since they are not incentivized to do so. This means that a light client could receive data for an invalid (non-existent) block. This is especially important for validiums that process a large amount of data, like zkPorter, and don’t want to make it available in a secure L1 (too expensive) or in a centralized provider (too insecure).
Mina is one example of a system which provides proofs of correct execution, and it goes even further, by creating a recursive SNARK that compresses the entire blockchain into a small, tens-of-KB-sized data structure. Other examples include zk-rollups like zkSync Era, Polygon zkEVM, Scroll, and Zeth, which prove execution using SNARKs. While these L2s can be verified with light clients without verifying the L1, using a more decentralized L1 as an additional settlement layer reduces trust assumptions.
Who provides the proof
With all the previous techniques, light client proofs can be both extremely secure and efficiently verified. However, there is still the question of who is providing the proof to the client, since this party can potentially hide information.
If a light client wallet simply connects to the wallet company’s server, the client must trust that the company isn’t hiding the latest blocks. This can lead to several types of attacks, like censoring data or providing incorrect state. In PoW and some non-slashing PoS protocols, the company can provide a proof of a valid fork of the blockchain which is not recognized or seen by others. Verifying that a certain blockchain is valid is not the same as verifying that it is the longest. This leads to even worse attacks, which can be mitigated with slashing and Merkle exclusion proofs.
Ideally, a wallet or bridge contract would receive proofs from multiple parties; for example, from multiple companies’ hardcoded server addresses, or even from random RPC nodes in the network. As long as one of these parties is honest, the client will receive the valid canonical proof, and lying or censoring become difficult. This assumption (that at least 1 of N parties is honest) is called the existential honesty assumption. Another way to phrase this is that a client needs to resist eclipse attacks, where the client is connected to only dishonest nodes and cannot access correct information.
It’s also worth noting that wallet developers must take care when using untrusted RPC nodes in the network to fetch proofs. These nodes have no performance guarantees, and could affect the user experience of a developer’s application. Instead, the client could opt to rely on a central server, and also fetch signatures from other nodes in the background to attest to the results. This approach (currently taken by Kevlar) can help bolster a light client’s security, without sacrificing user experience.).
Cryptoeconomic security
In PoS systems where signers don’t get slashed for creating fake blocks, there is a risk that dishonest validators will sign invalid headers or data and provide them to light clients. As a worst-case scenario, a 51% attack on a network where light clients don’t verify execution would be catastrophic. This is especially true in the context of a bridge, since an attacker could mint fake assets. Developers can discourage this sort of attack by writing a smart contract (or core L1 feature) that slashes the stake of nodes that sign invalid data – see this interesting proposal from Etan (Nimbus team), which talks about slashing for the Ethereum Sync Committee.
As explained in previous sections, light clients that verify both execution and DA, as well as consensus, are less vulnerable to dishonest validators. That said, slashing can still provide additional security by preventing certain attacks.
Privacy
Finally, let’s quickly cover one last consideration for some users: The privacy of the light client itself. Although using a light client can reduce reliance on centralized company servers, doing so can also expose the link between the user’s blockchain addresses and their IP to multiple random nodes instead. Some light client protocols like Neutrino (Bitcoin) can hide a user’s addresses when fetching data, but this might be harder for EVM systems and systems with a large amount of state. It’s possible that privacy infrastructure like Tor or Nym can help here, by hiding the user’s IP.
One potentially more secure way of providing privacy for light client wallet users is through the use of trusted execution environments (or TEEs) on the wallet server. The wallet server can encrypt the blockchain state’s data with a key that is only accessible from the TEE. When making a request, the user encrypts that request with the TEE’s key, delivers the message to the server, and the TEE processes the request without revealing the result to the server. This is not easy to do securely, and an efficient encrypted memory scheme is required, such as ORAM.